Using machine learning to perform deep statistical analysis on league of legends match data
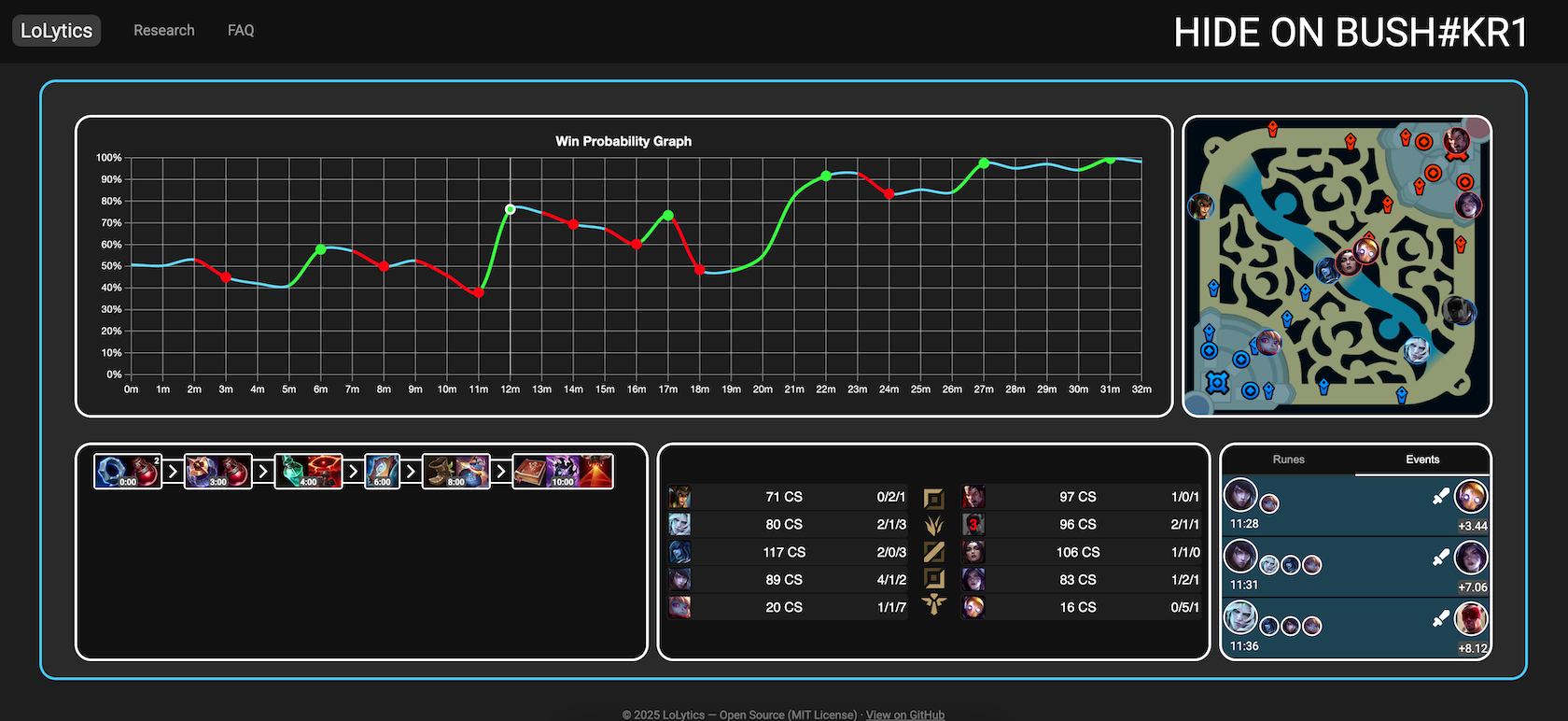
When I initially started this project, I just wanted to graph the win probability at the start of any game. After refining this idea further, I realized that win probability estimation at any given timestep is far more valuable. It allows for calculating metrics such as WPA which is very powerful in such a high dimensional strategy game like league of legends. I then had the vision of creating a web application that allows users to review their games in a very fast and efficient manner. They should be able to look up their match history, and after selecting a game, be presented with a collection of visuals to help them identify their mistakes and any events that cost them the win the most.
 https://thomasythuang.github.io/League-Predictor/
https://thomasythuang.github.io/League-Predictor/
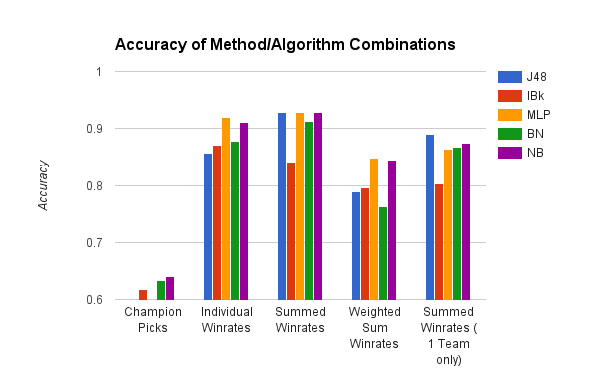
The first step was to develop the win probability estimation model. The first idea that came to my mind was to simply vectorize the current state of the game and pass that through a multi-layer perceptrion. I then looked up the latest machine learning research on the subject. Even after comparing Transformers, LSTMs, and GRUs, the best architecture by a large margin for win probability estimation is MLP.
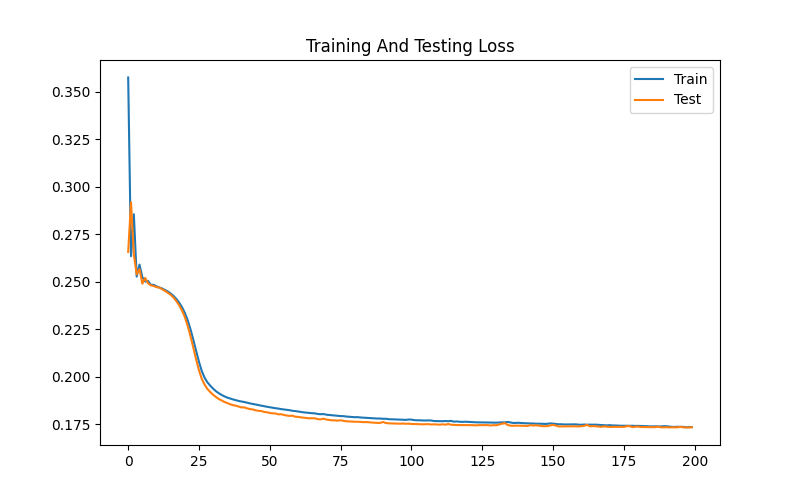
I used the Riot Games API to download about 540,000 games of league of legends timeline data. Each formatted was formatted in JSON and contained a list of frames which stored an array of events that happened in every minute. This allowed me to parse the events individually and reconstruct the state of the game at any given point during the game. In order to prevent data leaking and overfitting, I selected one random timestamp per game and stored the entire training and validation datasets using the LMDB format for fast data storage and retrieval during training. Due to the small size of the neural network and low latency from the dataset format, training the neural network was quite fast and the loss only required a couple hours to converge. It also displayed no initial signs of overfitting signalling good generalization capabilities which was later confirmed by the low ECE score on the testing set(2.97%).
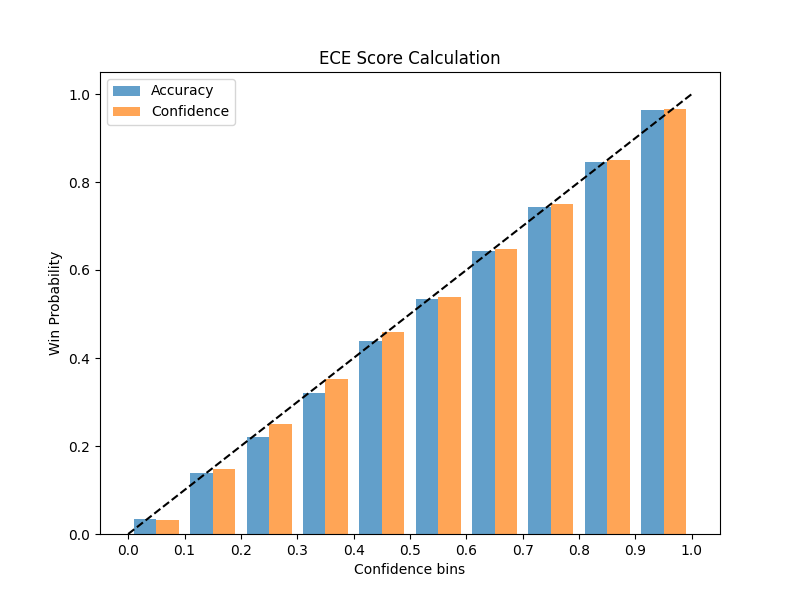
After having complete training, it was now time to properly test the model and ensure the app worked correctly. I wrote some integrity tests to ensure the model's predictions matched the webapp version and included these tests as part of the CI/CD pipeline. It was also important to calculate the functional metrics about the model which in my case was the above reliability diagram. I used temperature scaling to ensure the model is properly calibrated, and was able to achieve an Expected Calibration Error of 1.02% on the validation set.
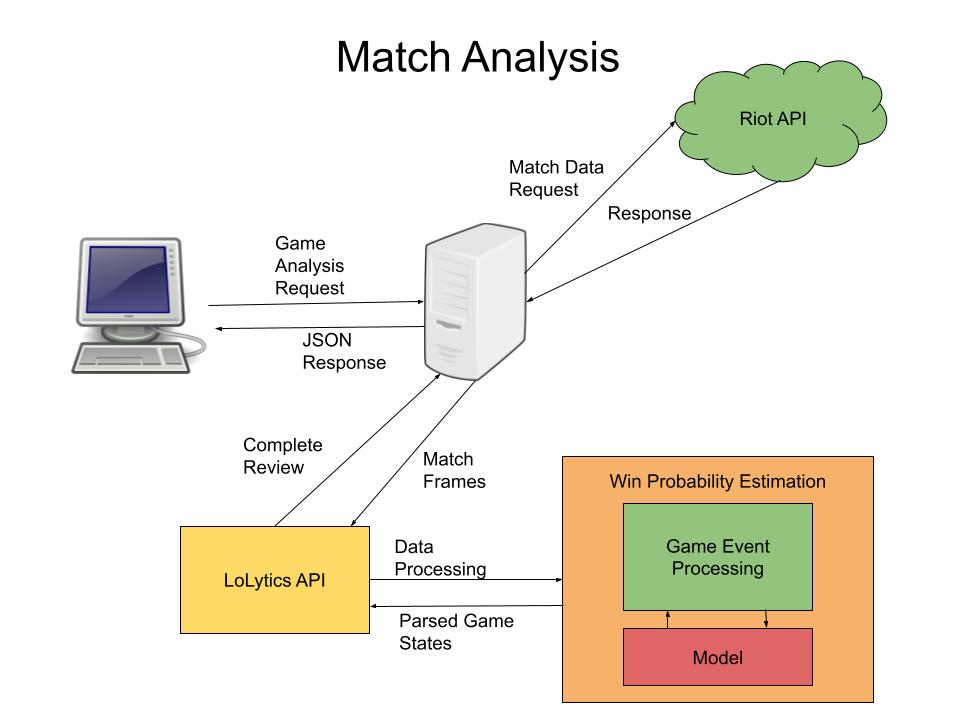
The final step was to deploy the model on a backend server. I used the ONNX library to load and deploy the model on the backend nodejs server. The model first had to be converted from a pytorch state dict to a .onnx binary first using the pytorch-onnx python package. After loading the model on the server and setting up the proper endpoints for the frontend-backend communication, the app was ready to use. I was even able to setup a feature to isolate per event win probability added in a specific game. The idea is quite simple, using the model we can predict win probability right before the event occured, and immediately afterwards. Subtracting these two number's gives us the *delta* or the difference between win probabilities before and after the event. This is also known as WPA or Win Probability Added which is commonly used in sports to quantify a player's contribution towards a win.